Self-Prompting Diffusion Transformer for Open-Vocabulary Scene Text Editing via In-Context Learning
Hongxi Li, Tong Wang, Chengjing Wu, Tianbao Liu, Jiangtao Yao, Xiaochao Qu, Xinxiao Wu, Luoqi Liu, and Ting Liu
In International Conference on Machine Learning, 2026
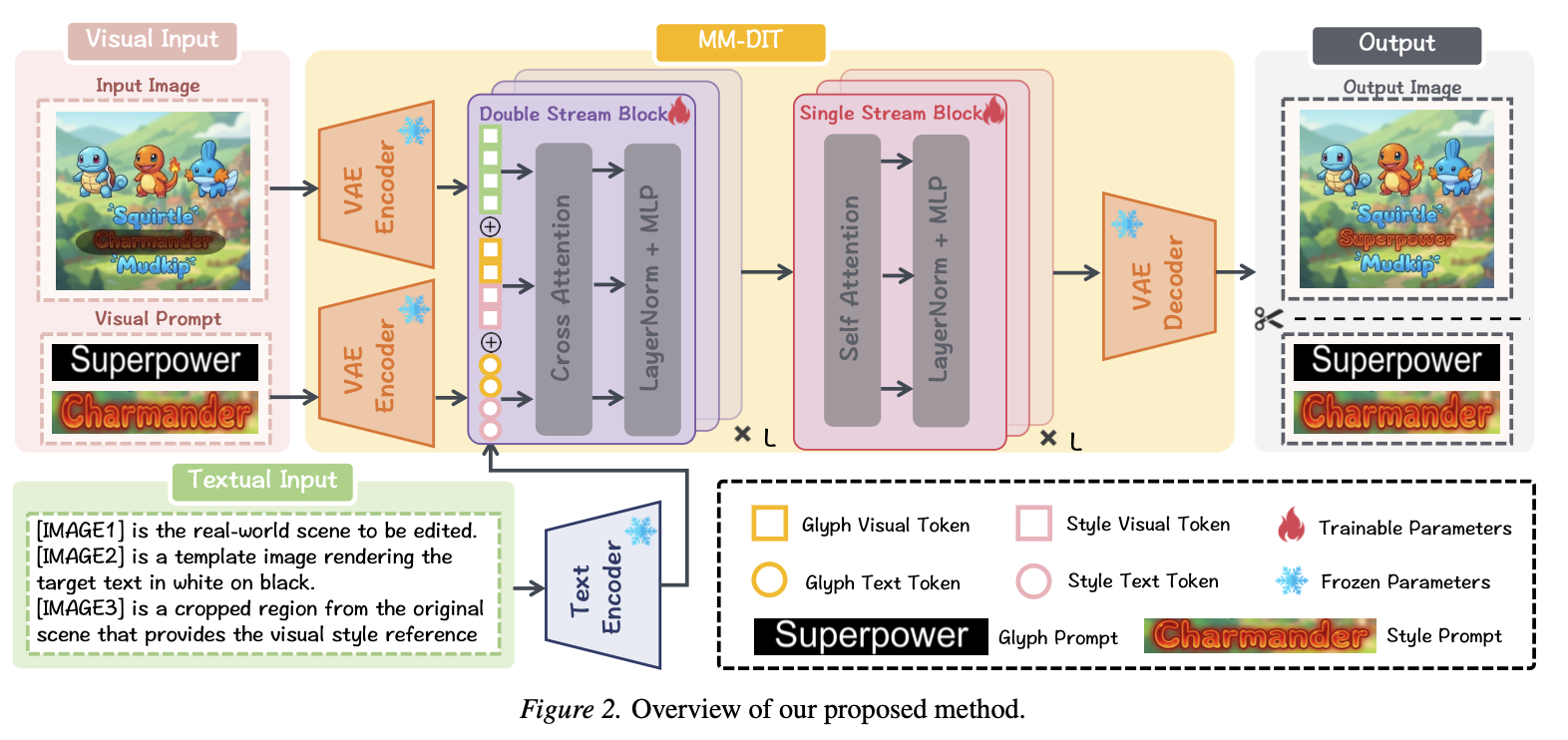
We propose a method that constructs style and glyph prompts directly from the original image without introducing additional encoders. A two-stage training strategy is used: the diffusion transformer is first trained on large-scale self-supervised data and then refined using a small set of paired images. By leveraging the in-context learning capability of the Multi-Modal Diffusion Transformer (MM-DiT), it achieves open-vocabulary and style-consistent text editing with state-of-the-art performance across various languages.